DICOM Sequences
DICOM allows a dataset to contain other nested datasets, which are encoded as “sequences”. The point of this structure is to allow repeating groups of data, so whilst such sequences often only contain a single dataset, the format is defined such that each sequence consists of a set of datasets. Of course, this structure lends itself perfectly to recursion, and some DICOM IODs such a Structured Reporting and the Radiotherapy Extensions can use sequences nested 5 or 6 deep !
The format of a sequence is as shown here:
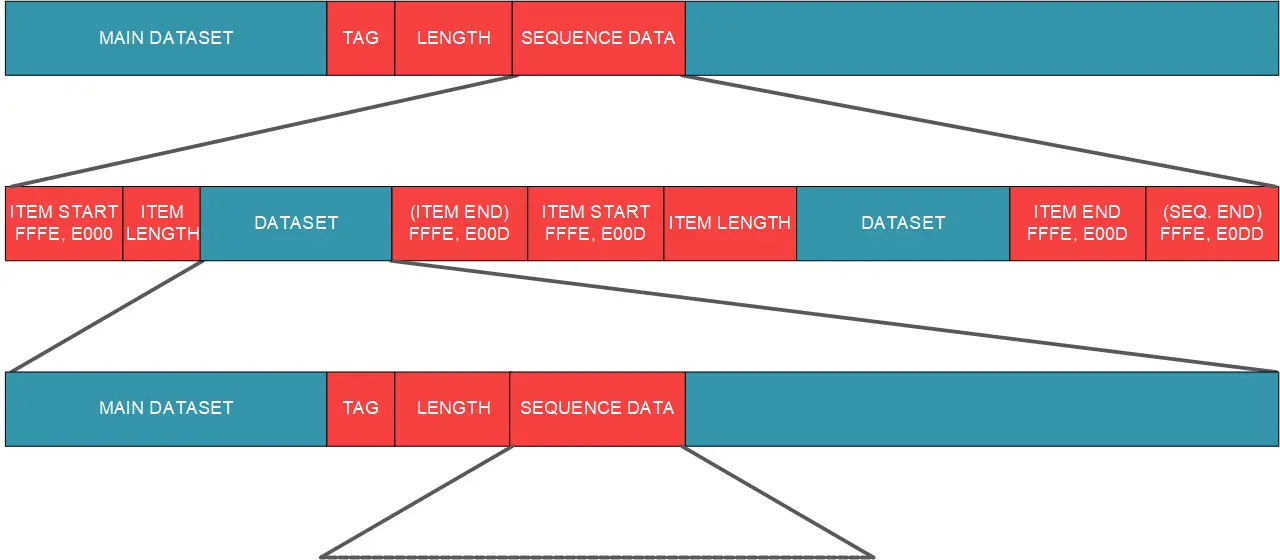
There are many different possible encoding of sequence data, using either explicit lengths for the lengths of the sequence as a whole and the datasets within it, or using an undefined length (FFFFFFFF) and end markers. Both are valid irrespective of the Transfer Syntax in use, but of course DicomObjects handles all the possible variations.
For advice on how to create sequences using DicomObjects, see the article on Adding Sequence Items
Note on encoding
In general, nested datasets are required to use the same encoding as the surrounding data. The only exception is if the sequence is labelled as having a VR of UN (as opposed to the normal SQ). In that case, they must be Implicit VR Little Endian. The logic is that UN can only occur where an application:
- Has received the data in Implicit VR Little Endian form
- Does not “know” what the VR should be for that item (e.g. if new or private)
- Is asked to write/send the data in explicit form.
In this case, the application would use a VR of UN, but since it would not know the true VR (and would not realise it was a sequence), then it would pass it out “as received” in its entirety, which would of course (as a consequence of point 1 above) be in Implicit VR Little Endian form.